We're building an agent harness that ships software without a human in the loop. Coding agents are already good at writing code; the gap is the job a QA engineer used to do — confirming the feature matches the spec, satisfies every functional and non-functional requirement, and doesn't break anything else for the user. Without a reliable answer to that question, a human has to step in by hand and the autonomy claim collapses. So the QA gate is the piece the rest of the harness hangs from. This post is about functional-verify, our attempt at building it.
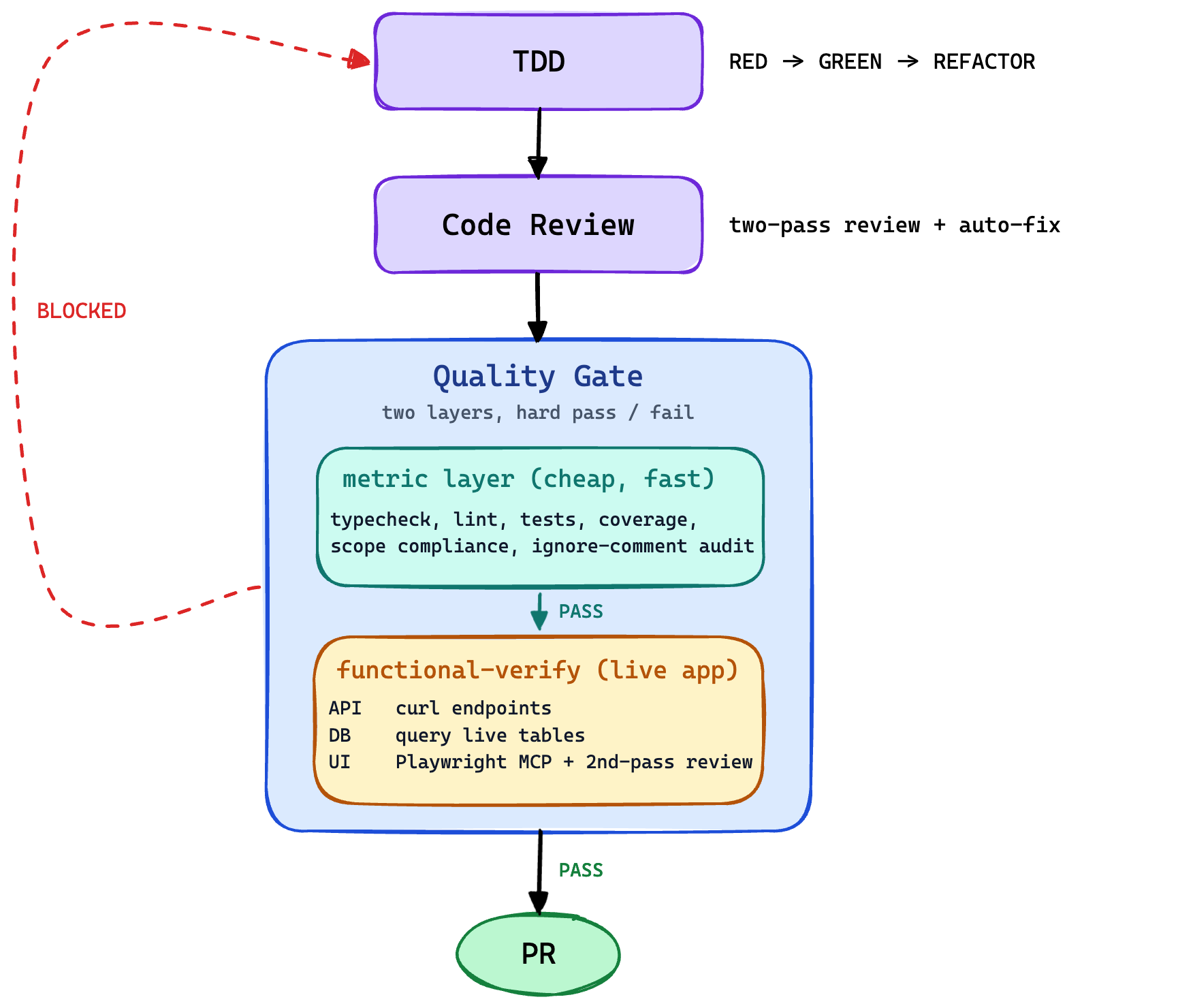
QA is the load-bearing piece
For a while we thought the hard part of building an agent harness would be writing the code. It isn't. Current coding agents write code about as well as a junior engineer with infinite patience and zero ego. They pick reasonable abstractions, they write tests alongside, they pass review more often than not.
The hard part is the job a QA engineer used to do. Confirm the feature matches the spec. Confirm every functional requirement holds. Confirm the non-functional ones — usability, performance, accessibility, security — are met. Confirm nothing else broke for the user. That's the part current agents are bad at, and it's the part that decides whether a harness can ship product without a person standing behind it.
Everything else in the harness — the planning agent, the dev agent, the review pass — produces an intermediate artifact. The QA gate is the only thing that grades the deliverable. Get it right and the code is disposable; no human needs to read it. Get it wrong and the autonomy claim falls over, because the only way left to verify the deliverable is to do it by hand. functional-verify is our attempt at that gate. It runs as a separate sub-agent, boots the application, hits the live API with curl, queries the live database, drives the UI in a real browser, and writes a proof report a reviewer can replay. We've been running it on every PR for about a month.
Two kinds of requirement the unit suite can't see
A spec defines value along two axes. Functional: given this input, does the system produce that output? Non-functional: does it do it in a way a real user would tolerate — fast enough, usable, accessible, secure. A QA gate that checks one and not the other isn't doing the job.
Unit tests are weak at both, for different reasons.
For functional requirements, tests use whatever fixtures the author chose. If the author's mental model of the input matches production, the tests catch bugs. If it doesn't — and it usually doesn't, because the author hasn't seen production yet — the tests pass against a feature that's broken. When the author is an agent, "the author hasn't seen production" is the default state. The agent has only ever seen the spec.
For non-functional requirements, tests don't even try. They render components in isolation, on a desktop, with a mouse. They don't know what a phone screen feels like, what a slow network looks like, or whether a contrast ratio fails. The dimensions the author didn't think to assert are the dimensions the suite is silent about. Silence is what the agent ships through.
functional-verify runs the application against both axes — the same way a human QA engineer would, except in code, on every PR.
What it does
The skill reads a ## Verification Scenarios section from the spec, or derives one scenario per acceptance criterion if the section is absent. Then for each scenario:
- Exercise the API. Send the request the spec describes and record exactly what came back: command sent, status code, response body.
- Exercise the database. Run the validation query against the live database and compare what's actually in there against what the spec says should be.
- Exercise the UI. Drive a real browser through the page: navigate, click, type, fill forms, wait for things to appear. Capture screenshots at phone, tablet, and desktop widths; record video of the full session; collect the network log and browser console errors; measure page-load timing and core web vitals on every navigation. For long pages, take overlapping slices so nothing is missed below the fold.
- Write the proof report. A verdict for each scenario, plus a coverage table that maps every requirement and edge case in the spec to the evidence file that proves it.
The interesting parts aren't the steps. They're how the skill grades what comes back, and what counts as evidence.
What that looks like in practice
The shape this takes depends on the feature, so it's easier to show than describe. Here's a flow we run a lot — newsletter signup. The spec says a visitor enters their email on the landing page, hits subscribe, receives a confirmation email, the email renders properly on phone and desktop, and every link inside it resolves to the right place. A human QA engineer would walk that whole flow by hand. The verifier walks it for them, on every PR:
- Drive a real browser to the landing page, type a test email into the subscribe form, click submit, screenshot the success state.
- Query the database for the new subscriber row; check the fields match the spec.
- Poll the test inbox until the confirmation email arrives. Fail the scenario if it doesn't show up inside the timeout.
- Render the email body at phone and desktop widths, screenshot each, record computed styles for anything the spec calls out (button size, link contrast, alt text on images).
- Extract every link from the email body, follow each one, record the status code and the page it lands on.
- Write each step's evidence into the proof report — the screenshots, the session video, the SQL rows, the email payload, the link traces, the load-time numbers.
Throughout the walk, the harness records video of every UI step, captures the network log, and times every page load and API call against the budget the spec set. None of that is novel. A careful QA engineer would do most of it. What's novel is that the harness does it without one — on every PR, without anyone asking — and the proof report is the trace of the whole walk. Cross-system flows like this are exactly the shape of bug a unit suite cannot reach, and exactly the shape of feature a user actually experiences.
Every claim cites evidence the reviewer can replay
Hand a vision model a screenshot and ask if the page looks fine, and it will tell you yes. Hand it a 200 response and ask if the API works, same answer. The defense has to be structural, so the skill rejects bare adjectives. Every claim must be grounded in something the reviewer can rerun or replay: an HTTP response body, a SQL row, a getBoundingClientRect() rect, a quoted DOM string, a computed style value, a numeric latency or page-load time, a frame from the session video, an entry from the network log. "Polished", "looks off", and "works fine" are explicitly banned.
The two cases below are the two failure modes — one functional, one non-functional — that motivated the whole project.
Functional: a backend regression the test fixtures hid
A change landed last month that passed every unit test and would have silently shipped an empty newsletter the next morning.
The agent had swapped out the component that fetches a page and converts it to markdown. Downstream, an LLM reads that markdown, picks the URLs worth indexing, and returns them as a list. A matcher then checks each returned URL against the markdown with a literal substring search. After the swap, the converter started emitting relative paths (/news/claude-opus-4-7) while the LLM kept returning absolute URLs (https://anthropic.com/news/claude-opus-4-7). The substring check never matched. Every chosen post would have been silently dropped.
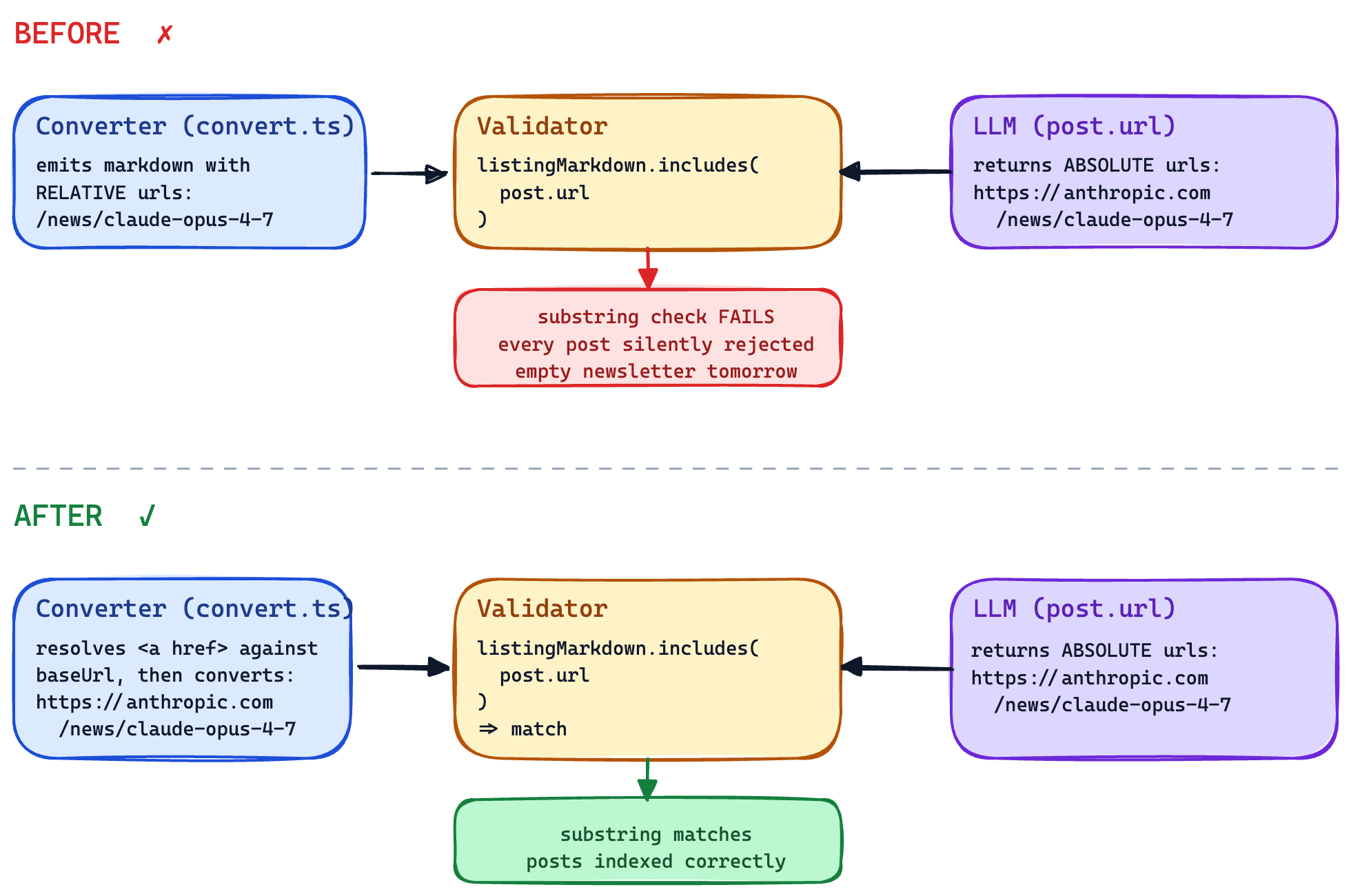
Every test fixture in the suite happened to use absolute URLs. The substring check matched in tests because the tests had never seen a relative URL in their lives. The verifier was the first thing in the pipeline to ever hand the converter a real production page, and the first thing to ever fail. The bug had been reachable for as long as the suite existed; nothing had ever reached it.
The fix was a one-liner. The interesting part wasn't the fix — it was that nothing in the upstream pipeline could possibly have caught this. The dev agent wrote tests against its own mental model. The mental model was wrong, in the same way as the implementation. The only way to find out was to run the application and watch it behave.
A separate scenario in the same report failed for an unrelated reason: an external API key was out of credit. The verifier didn't paper over it. It logged the error, marked the scenario as an external blocker, and noted the same code path would have failed identically before the change. We care about that more than we care about the bug it caught. A QA gate that lies when it can't run the check is worse than no gate at all — it generates false confidence the rest of the harness then runs on.
Non-functional: a UI regression the suite was never going to catch
Different feature, same skill. The agent had just made the public archive page mobile-friendly. Tests passed. We opened it on a laptop. It looked great.
The verifier opened the same page on a phone-sized window and tried to tap a story. It couldn't. The headlines were thin strips of text, much shorter than a thumb is wide, so any attempted tap landed somewhere in a cluster of three headlines and never reliably on the one you wanted. The agent had built a list you could not actually use on a phone.
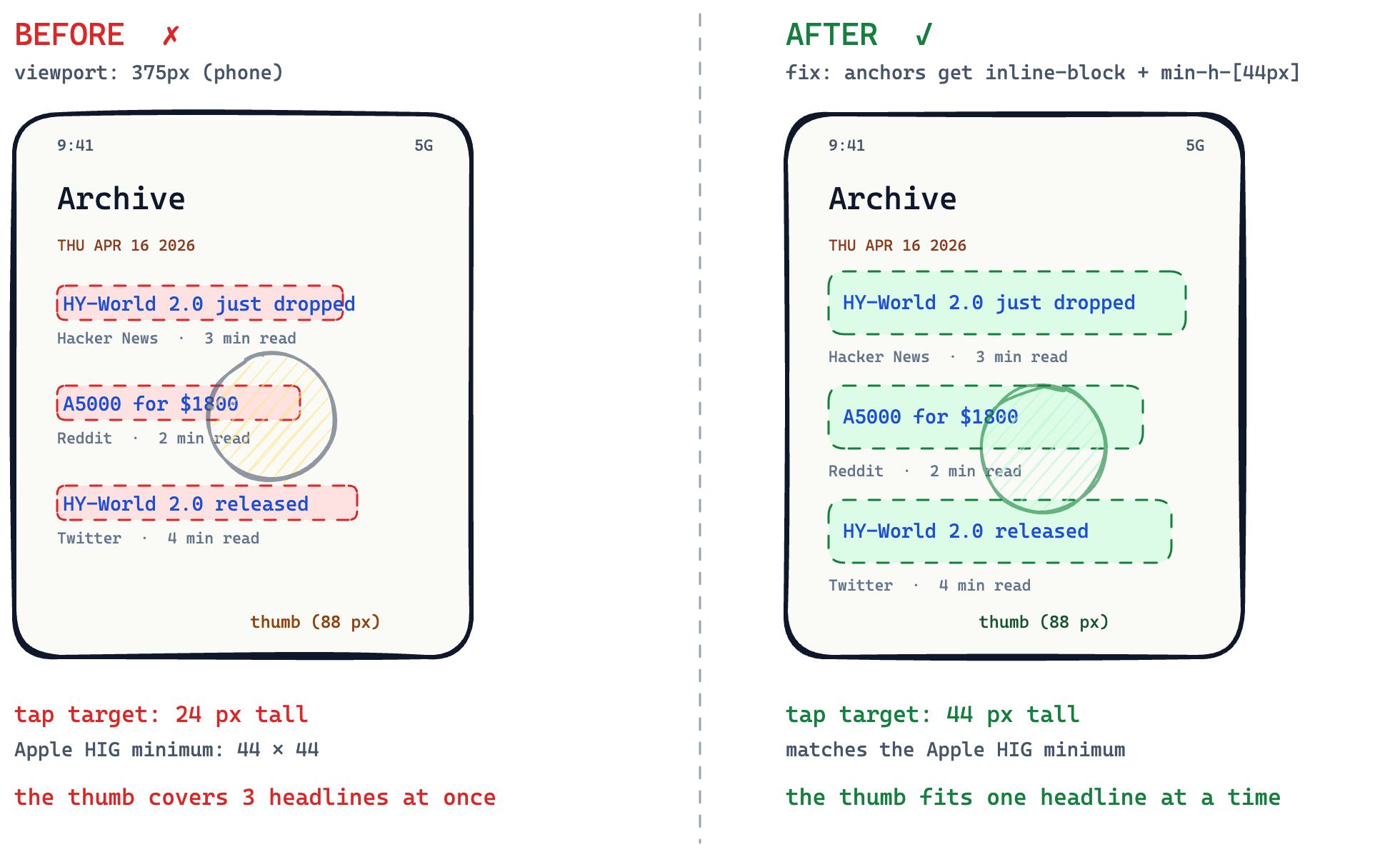
The verifier put the actual numbers in the report. Each headline was 24 pixels tall. A comfortable tap target on a phone is at least 44. That's the whole bug, in one sentence the reviewer can re-check. A real QA pass would have caught it in five seconds. Without one, the harness has to.
The through-line of both cases: the suite was green, the unit tests were asserting against the agent's mental model, the agent's mental model was wrong, and the verifier was the first thing in the pipeline that ever booted the application and watched it behave the way a user would.
Why the verifier can't know the implementer
functional-verify runs as a separate sub-agent with no view of the code that produced the feature. The dev agent wrote the code and the tests; the verifier sees only a running application and a spec. No shared memory. No shared incentive to declare the work done.
That separation is the whole point. An agent that writes the feature and also writes the "verified, all green" report will return green every single time. It isn't malicious. It's doing what an agent does when you ask it to grade its own work — looking for the cheapest path to a checkbox, finding the one that says "approved," and ticking it. Healthy engineering orgs solved this problem long ago by giving QA the standing to say no to dev. The same pattern needs to exist inside the harness for the same reason. Otherwise the gate is theatre, not a check.
How the proof report ends up on the PR
Every run writes one folder:
docs/spec/<feature>/verification/proof-report.md
docs/spec/<feature>/verification/api/<scenario-id>.txt
docs/spec/<feature>/verification/static/<scenario-id>.txt
docs/spec/<feature>/verification/ui/<route>-<viewport>.png
docs/spec/<feature>/verification/ui/<route>-<viewport>-slice-NN.png
docs/spec/<feature>/verification/ui/observations.md
The orchestrator's commit stage picks all of it up and includes it in the PR. The reviewer opens proof-report.md and walks through a summary table (scenario, type, verdict), the API/DB/UI evidence inline with curl commands and SQL rows and screenshots, a spec-coverage table that maps every requirement to the file that proves it, and a "Not executed" section listing what the skill couldn't check. If the reviewer disagrees with a verdict, the rect, the curl, the row, or the screenshot is right there to argue against.
For now, a human reviewer is still in the loop. The check produces evidence; a person reads it and clicks approve. That's a deliberate intermediate step — we don't trust the gate enough yet to let it auto-merge. Every false pass we find tightens the gate; every honest "not verified" tells us where it's still soft. The shape of the journey is: less and less reason for a human to look, until eventually there isn't one.
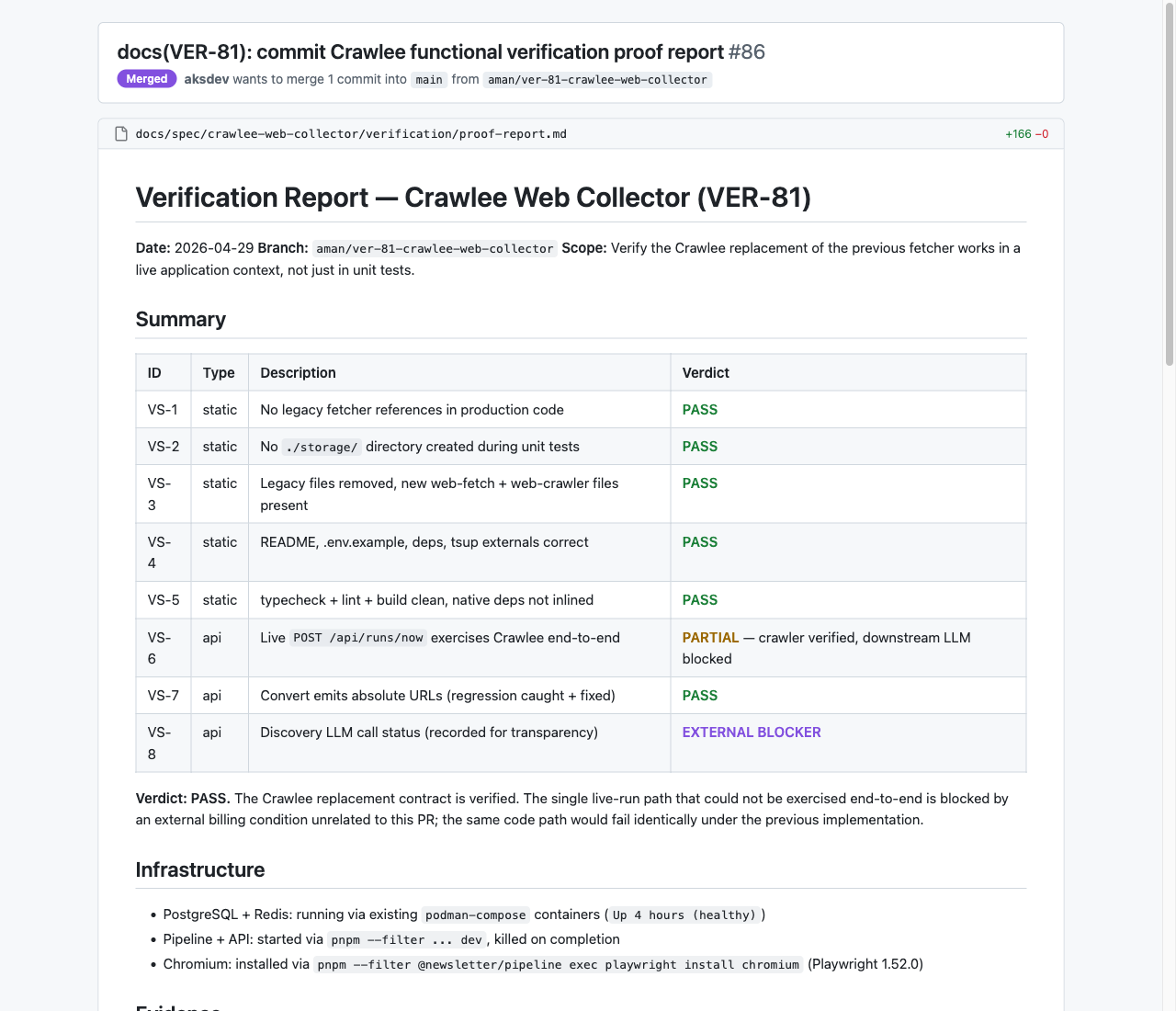
A real proof report on a merged PR. Six scenarios PASS, one PARTIAL, one EXTERNAL BLOCKER. The reviewer sees this before approving.
Where this leaves us
functional-verify isn't the finished version of the gate. The first few weeks of running it were a mess. It marked scenarios PASS because the curl came back. It cited screenshots that didn't exist. It declared coverage when it had run half the spec. Most of the work since then has been forcing the verifier to fail loudly when it can't satisfy a check, instead of quietly approximating one. Every false pass we caught tightened the gate. Every honest "not verified" told us where the gate was still soft. That's the loop the rest of the work runs on.
There are categories the gate still misses. We measure page-level performance — load time, paint, core web vitals — but not performance under load, where concurrency and sustained throughput would have to be exercised. We don't yet test security posture, anything a touch-hold gesture or a real-device sensor is needed for, or anything that depends on an external service unreachable at run time. Each gap is a place a human still has to look. Closing them, one failure mode at a time, is most of what we'll be working on next.
If the gate gets good enough, the harness becomes autonomous in the way we mean it: the code is an artifact, the proof report is the deliverable, no human needs to be in the loop. If the gate stays soft, the harness can write code all day and never ship a product. That's why we treat this as the piece most worth investing in. And if you're building something similar, the question that decides whether you have a real gate or a piece of theatre is this: who in your loop is structurally allowed to say no? If the answer is the agent that wrote the code, you have theatre.
]]>