Strot - The API Scraper
Strot (Sanskrit meaning source) is an AI agent which scrapes web api:
- Instead of scraping the dom, identifies the right api call.
- Fast, reliable, complete data scraping for listing data is possible via API scraping.
- Strot figures the api call so you don't have to.
What if ... ?
When working with clients, we figured that they frequently need to scrape listing data like reviews and product listings. The DOM Scraping solutions don't give complete data.
When is comes to scraping reviews, things CAN BE slightly different than running playwright scripts. That's the idea we started with!
It stems from the insights on browsing shopify. Since, shopify has plugin ecosystem, a lot of reviews come from plugins. They give the reviews in html / json form via api that the page renders. Since, reviews - if they are worthwhile - would be in 100s for a given product, it would be very unlikely that someone with good web-dev practices will send all of them on one shot. There MUST be a second call (pagination) that requests for further reviews for the given product.
What if ... we could scrape listing data via intercepting AJAX calls that are made from the browser itself?
The Genesis
Hence, an experiment is born - called strot. In sanskrit it means source. We are trying to get to the ajax calls that gets us listing data.
The review scraping problem sits at a unique position. There are always MANY reviews which either causes cost ballooning no matter which existing approach you take.
Strot is the only project which can scrape the data available as api call - at all - using natural language.
| Feature | Playwright | LLM Scraper | Strot (Ours) |
|---|---|---|---|
| Cost | Infrastructure costs for automation | Pay per page + LLM inference | One-time API discovery |
| Maintenance | High - UI changes break scripts | Medium - prompt engineering needed | Low - APIs rarely change |
| Intelligence Required | High - manual scraper | High - per page analysis | One-time - for API discovery |
| Scalability | Poor - loads full pages | Expensive - each page costs $ | Excellent - pagination via API |
| Setup Complexity | Medium - browser automation | Low - plug and play | Low - plug and play |
| Uniqueness | Common approach | Common approach | Unique to us |
So, IF we could find the ajax call → we only have to spend time figuring out the API call. and voila! You can simply call API - this is cheapest, fastest, most reliable approach of all.
And the unique to us. Hence, we took a bite.
But the challenge is which api call is most relevnt for scraping reviews ? we solve this by capturing screenshot, visually analysing if review is preseng in the screenshot. Then we find a matching ajax call that has a similar content. Voila!
The challenges of current approaches
Each traditional approach faces fundamental limitations that compound at scale:
Most products with worthwhile reviews have 100-10,000+ reviews. Traditional approaches cost:
- Playwright: 100 reviews × 3 pages × 10s load time = 30+ minutes
- LLM Scraper: 100 reviews × $0.10 per page = $10+ per product
- Manual API: 100 reviews × 15min engineer time = $200+ per product
Strot's approach: 100 reviews × 0.1s API call = 10 seconds total.
Technical Details
Traditional DOM scraping faces several fundamental limitations:
- Rate Limiting: Websites throttle based on page loads, not API calls
- Bot Detection: Full page loads trigger anti-bot measures (Cloudflare, etc.)
- Resource Overhead: Loading entire DOM + assets vs lightweight JSON responses
- Maintenance Burden: CSS selectors break with UI changes, APIs rarely change
AJAX interception bypasses these by operating at the data layer, not presentation layer.
Our matching algorithm works in stages:
- Content Extraction: Extract review text from screenshots using OCR + Vision LLM
- API Response Analysis: Parse all captured AJAX responses for text content
- Fuzzy String Matching: Use algorithms like Levenshtein distance, Jaccard similarity
- Confidence Scoring:
- Text overlap ratio (>90% = high confidence)
- JSON structure analysis (nested objects, review-like fields)
- Response size correlation with visible review count
Edge Case Handling:
- Paginated responses (partial matches expected)
- Localized content (different languages)
- Dynamic timestamps/IDs (filter out volatile fields)
Since we have to do the hard part of finding the right AJAX call ONLY once, it means that we can use augmentation from vision understanding to make it more accurate.
This helps by:
- Confirms which API calls actually render user-visible content.
- Handles cases where multiple API calls contain review data
- Eliminates false positives from internal/admin API calls
The codegen
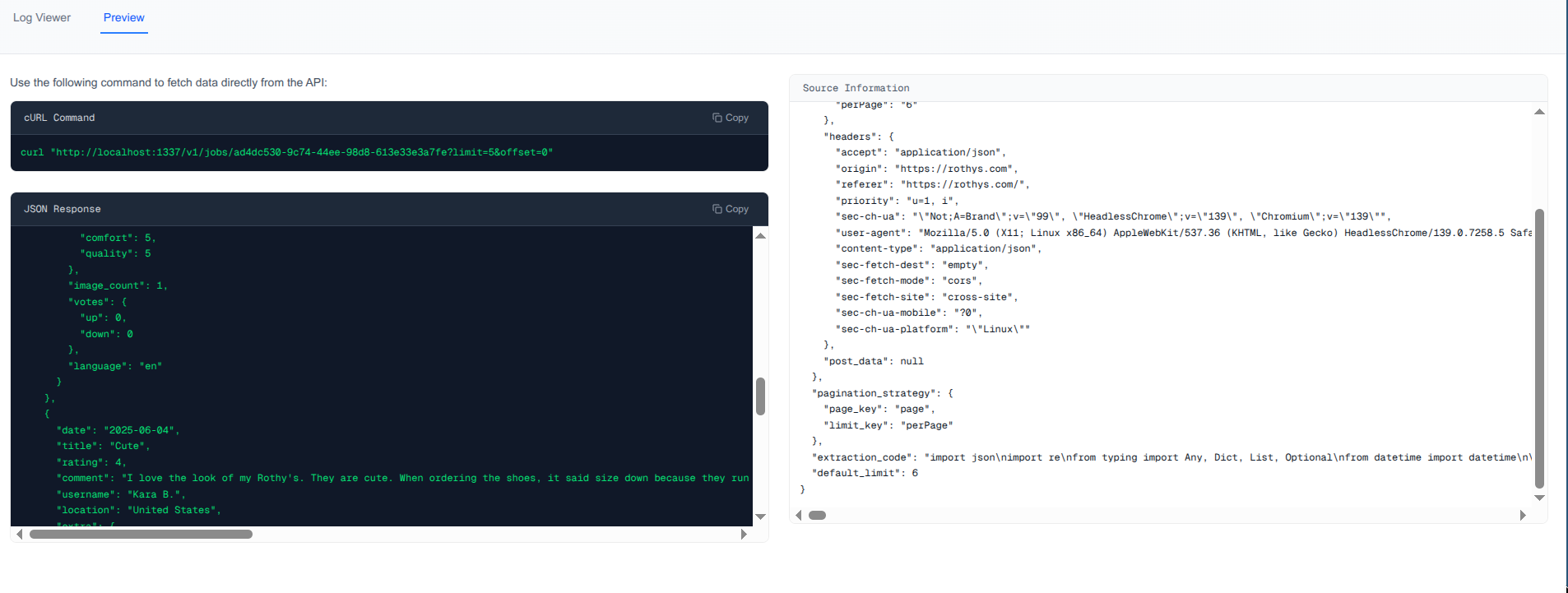
We internally represent all the relevant information as json. This helps us to generate http client in any language of choice. Calling this API endpoint in succession will give all the reviews.
Iteratively Improving via Error Analysis and Evals
Evals were central to us while building this. We had three tiered system for evals that served us well.
- Does the analysis identify the right ajax call?
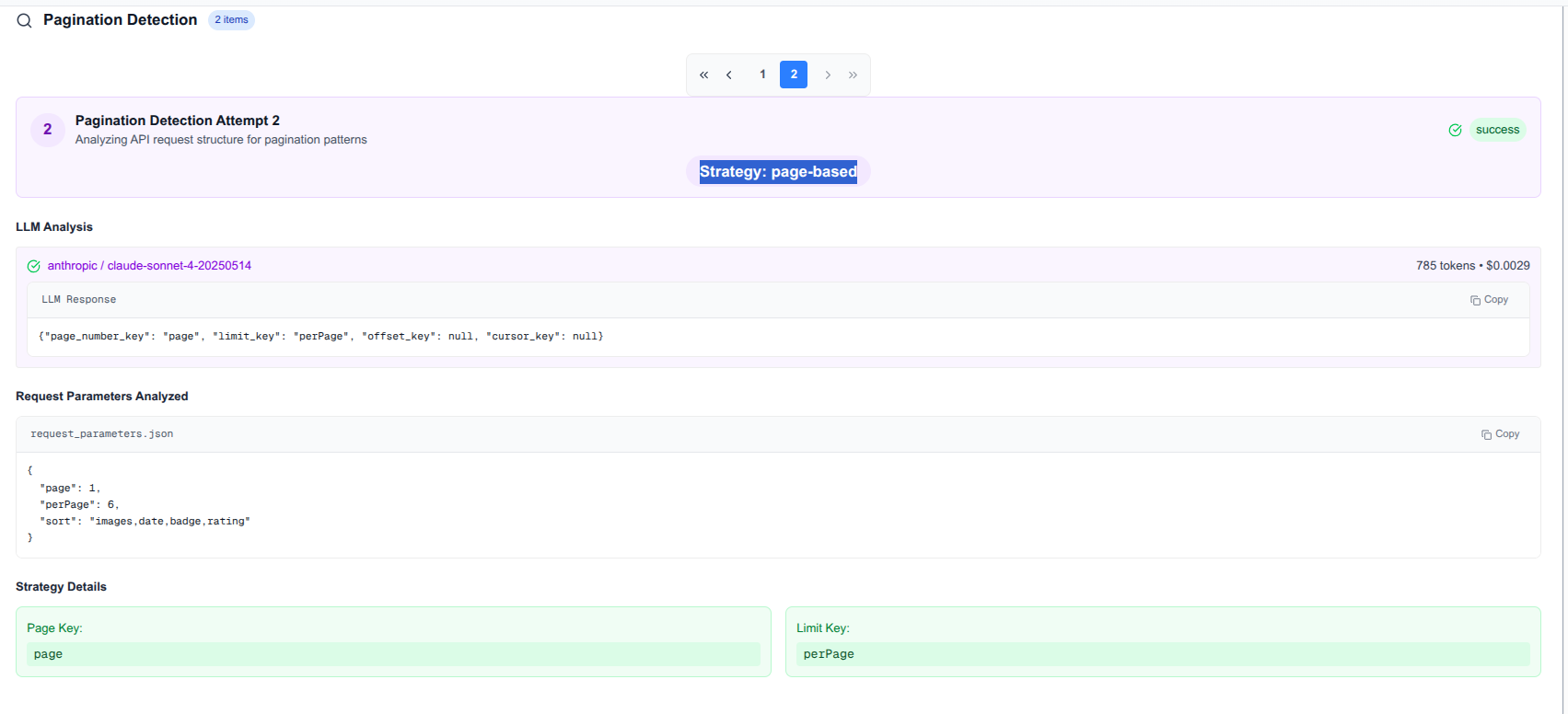
- Is the pagination strategy detection done correctly?
- Is the http api (codegen) able to get all the reviews?
Error Analysis
This was the most consuming element for us until we vibe-coded initial version of this dashboard to see the logs as data.
Our observability dashboard processes shows data from:
- Application logs (structured JSON)
- LLM API call traces (OpenAI/Anthropic)
- Playwright screenshots
This helps to do the error analysis and improve the system iteratively.
Here is a quick peek over the dashboard we made to do the error analysis:
This shows us the cost and token usage:

This shows us the step by step observability into what is happening:
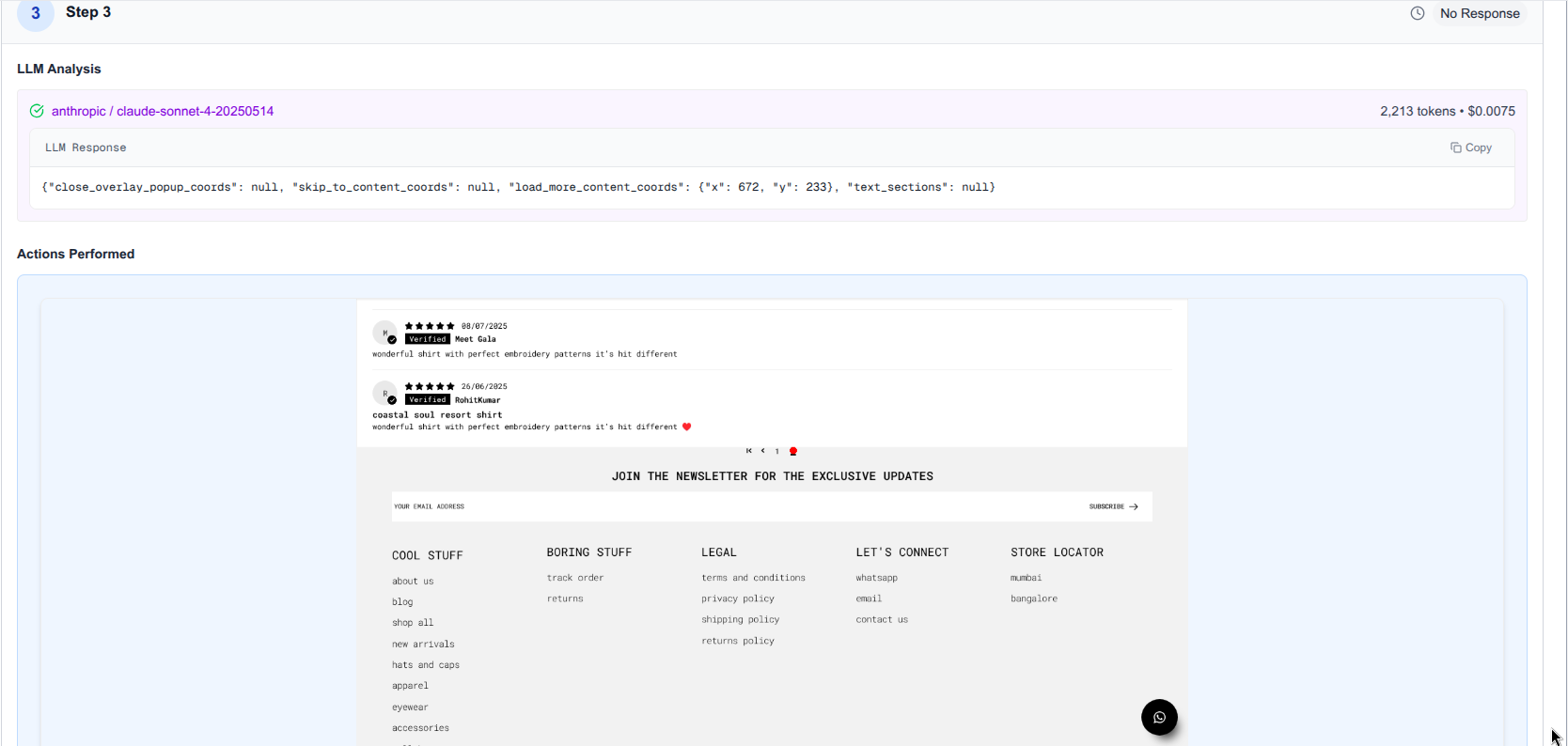
Pagination
Codegen
We are also learning. This was our attempt at scraping the webpage and using the visual understanding of image models to get to the reviews faster. if you feel this can be improved, feel free to share those with us on github-issues.
Roadmap
- We are already on a path to make this a generic scraper. Currently, our evals sets show the tracking progress on various websites. It will be released soon.
- if you would like us to host this as a service for you, we are more than happy to. Come chat with us at [contact email]