How we made a 13 GB LLM container cold-start in 40 seconds


A 13 GB GPT-OSS-20B inference container: 571s → 40.65s. A 2.4 GB Llama-3.2 container: 91s → 7.4s. Same hardware, same app, only the image format and snapshotter config changed.
The obvious first move — lazy loading — made things 66% slower. The biggest single win came from a stack of hidden config knobs we had to read the snapshotter's Go source to find. The last bottleneck wasn't in containerd at all; it was the AWS EBS default write ceiling.
If you ship LLM images and your cold start is over a minute, this is for you.
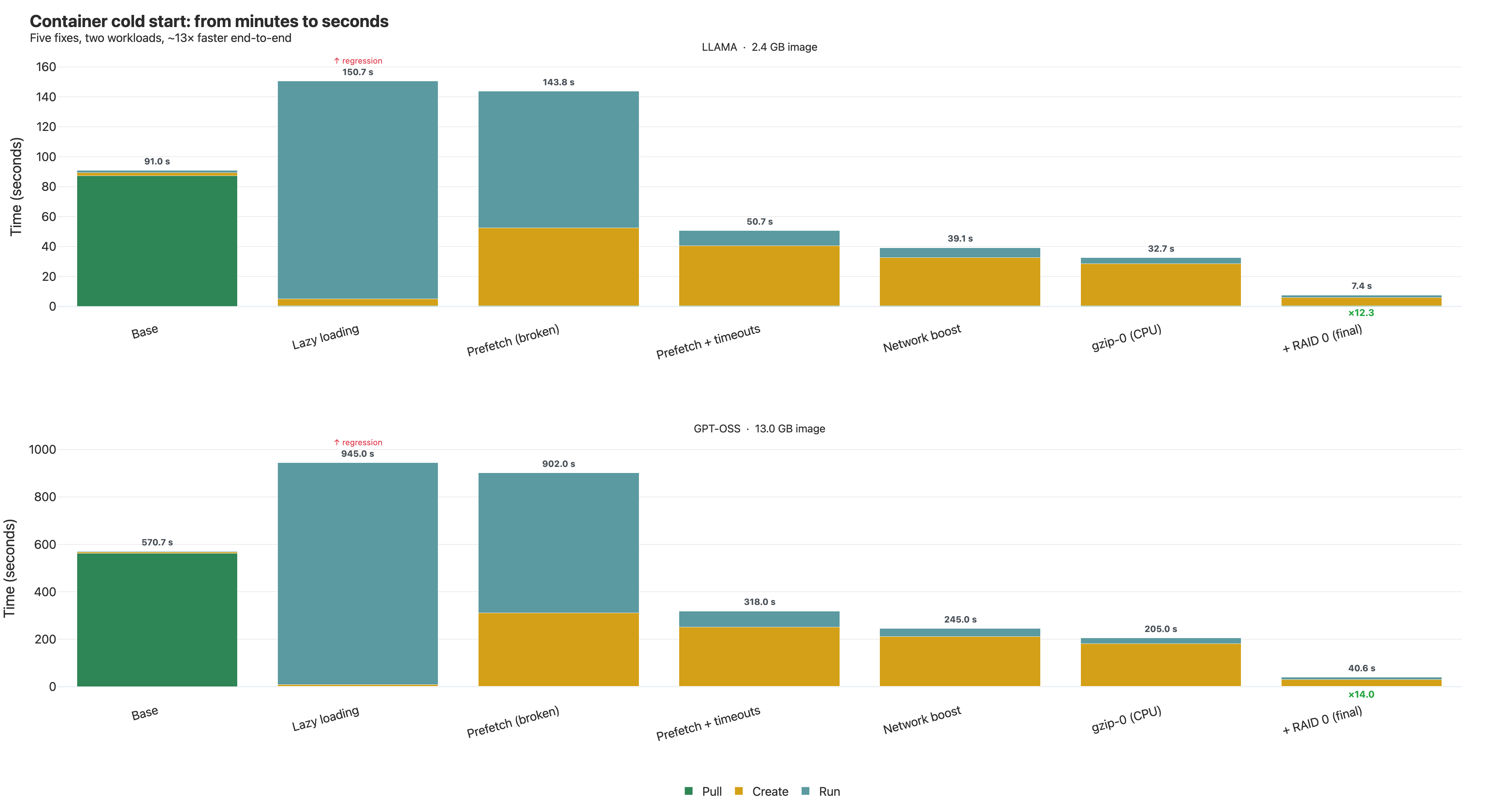
If you ship a multi-gigabyte ML container — Hugging Face weights baked in, PyTorch + transformers, a FastAPI server — and you've watched the deploy take five-plus minutes from docker run to first inference, this post is the playbook we wish we had.